PrecepTron¶
An open LLM judge for scalable, physician-level evaluation of clinical reasoning.
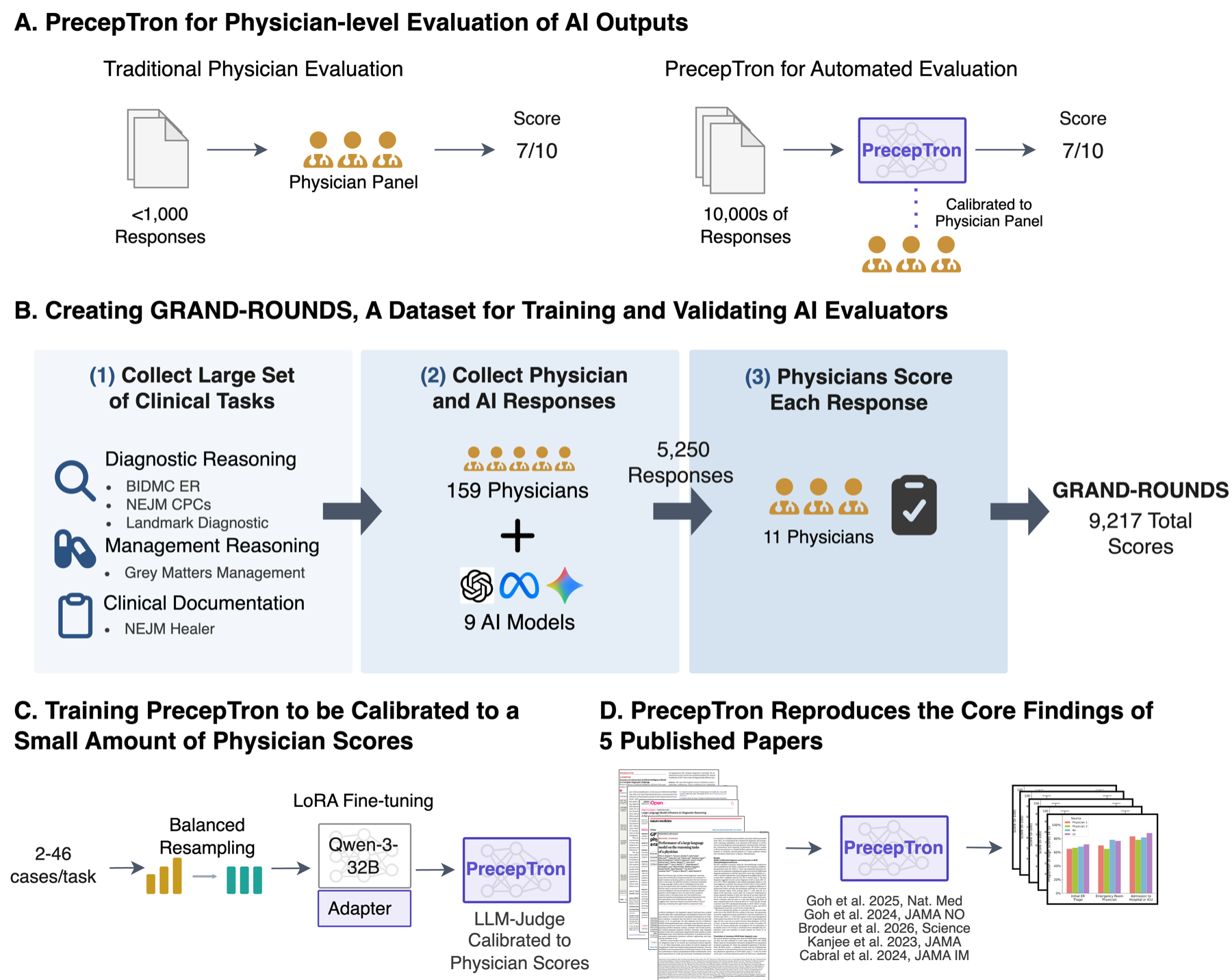
PrecepTron is a fine-tuned 32B model that grades open-ended clinical reasoning against validated rubrics, calibrated to a physician panel from only a handful of scored examples per task. It is small enough to run on local hospital infrastructure, reaches physician-level agreement, and lets researchers evaluate clinical LLM outputs at a scale that manual physician grading cannot reach.
To develop and validate it, we built GRAND-ROUNDS, a benchmark of 9,217 physician scores across 5,250 open-ended clinical responses — spanning diagnostic reasoning, management, and clinical documentation — drawn from seven published studies and graded by 11 physicians.
Resources¶
- 🤗 Models & dataset on Hugging Face — the PrecepTron-32B judges and the GRAND-ROUNDS benchmark.
- 📊 GRAND-ROUNDS dataset
- 💻 Code on GitHub — coming soon.
- 📄 Paper (arXiv) — coming soon.
Citation¶
@article{buckley2026preceptron,
title = {Evaluating Medical AI without Physicians},
author = {Buckley, Thomas A. and Kanjee, Zahir and Brodeur, Peter G. and
Crowe, Byron and Pettinato, Anthony M. and Shah, Aashna P. and
Haimovich, Adrian D. and McCoy, Liam G. and Restrepo, Daniel and
Goh, Ethan and Chen, Jonathan H. and Zwaan, Laura and
Goodman, Katherine E. and Morgan, Daniel J. and
Abdulnour, Raja-Elie E. and Rodman, Adam and Manrai, Arjun K.},
year = {2026},
note = {Preprint, forthcoming}
}